Article Text

Abstract
Background Neuroimaging techniques provide rich and accurate measures of brain structure and function, and have become one of the most popular methods in mental health and neuroscience research. Rapidly growing neuroimaging research generates massive amounts of data, bringing new challenges in data collection, large-scale data management, efficient computing requirements and data mining and analyses.
Aims To tackle the challenges and promote the application of neuroimaging technology in clinical practice, we developed an integrated neuroimaging cloud (INCloud). INCloud provides a full-stack solution for the entire process of large-scale neuroimaging data collection, management, analysis and clinical applications.
Methods INCloud consists of data acquisition systems, a data warehouse, automatic multimodal image quality check and processing systems, a brain feature library, a high-performance computing cluster and computer-aided diagnosis systems (CADS) for mental disorders. A unique design of INCloud is the brain feature library that converts the unit of data management from image to image features such as hippocampal volume. Connecting the CADS to the scientific database, INCloud allows the accumulation of scientific data to continuously improve the accuracy of objective diagnosis of mental disorders.
Results Users can manage and analyze neuroimaging data on INCloud, without the need to download them to the local device. INCloud users can query, manage, analyze and share image features based on customized criteria. Several examples of 'mega-analyses' based on the brain feature library are shown.
Conclusions Compared with traditional neuroimaging acquisition and analysis workflow, INCloud features safe and convenient data management and sharing, reduced technical requirements for researchers, high-efficiency computing and data mining, and straightforward translations to clinical service. The design and implementation of the system are also applicable to imaging research platforms in other fields.
- neuroimaging
- computing system
- cloud computing
- data analysis system
- computer-aided diagnosis system
- data sharing
Data availability statement
Data may be obtained from a third party and are not publicly available.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
- neuroimaging
- computing system
- cloud computing
- data analysis system
- computer-aided diagnosis system
- data sharing
Key messages
The known
Rapidly growing neuroimaging research generates massive amounts of data.
A cloud solution helps standardise the acquisition, management, analyses and utilization of large-scale neuroimaging data.
There is a need to make neuroimaging research data available to serve clinical practice in the diagnosis and treatment of mental disorders.
The new
INCloud provides a full-stack solution for the entire process of large-scale neuroimaging data collection, management, analysis, and clinical applications.
INCloud helps standardize the acquisition and pre-processing of neuroimaging data, making it easier to aggregate data collected by multiple teams.
INCloud implements a brain feature library that allows users to query, manage, analyze and share brain features, and therefore accelerates the utilisation of neuroimaging data.
INCloud connects scientific data to CADs so that research data can contribute to clinical service.
Introduction
Brain research is essential for understanding, diagnosis and treatment of mental disorders. Neuroimaging precisely reflects the structure and function of the human brain and has become a commonly used technique in brain research.1–8 Various neuroimaging modalities and analytic methodologies have been applied to characterise the brain of those with mental disorders.9–11 The deployment of various brain research projects has significantly accelerated neuroimaging research on normal populations and people with mental illness. Accordingly, there are new challenges to data collection, data management and sharing, computational resources and data mining.
Neuroimaging data collected by different research groups often have inconsistent scanning parameters, which may affect the quality consistency of the data and harm the statistical power of the analyses.12 13 Before data collection, the efforts of the neuroimaging centre to standardise and accurately manage scanning parameters can help unify data quality and promote more efficient accumulation and sharing of neuroimaging data. At the same time, standardised subject registration and scanning procedures are required to maximise the consistency of the data collection process and provide an important foundation for neuroimaging data management, standardised processing and connection with clinical information.
The management of large-scale neuroimaging data, especially for mental disorders, is another challenge for imaging centres. Specifically, the diverse diagnosis of mental illness and the multiple imaging modalities used in research bring complexity to the centralised management and cleaning of data. Data collection and analysis are usually carried out in the form of a team (multiperson) or teamwork (multiteam), which brings challenges to data authority management and security assurance. There are some large-scale neuroimaging data management and sharing systems, such as LONI\IDA (The Image and Data Archive at the Laboratory of Neuro Imaging),14 COINS (The Collaborative Informatics and Neuroimaging Suite),15 NITRC-IR (The Neuroimaging Informatics Tools and Resources Clearinghouse Image Repository)16 and XNAT (The Extensible Neuroimaging Archive Toolkit)17 systems (table 1). These systems are versatile and emphasise the authority management of data, so the unit of data management is the dataset. It should be emphasised that the neuroimaging data management system is not equivalent to the data warehouse. In addition to the management of access rights and sharing, it is also necessary to consider how to connect each individual’s specific scan or imaging features to other data, such as scans using other imaging modalities and clinical phenotypes. Therefore, we need a more sophisticated data management system.
Comparison between INCloud and other neuroimaging platforms
The processing of neuroimages usually relies on complex calculations that combine multiple general or specialised software programs, such as Matlab and FreeSurfer. Installing this software on personal computers and maintaining their operation is not a simple task. The neuroimaging research of many non-technically-oriented researchers has been hindered by this starting point. There is research evidence that the software version and even the operating system version have a systematic influence on the calculation results. For example, FreeSurfer running on different versions of Linux systems will give different skin thickness estimation results. In addition, with the rapid increase in the amount of data and the increase in computational complexity, the performance requirements of computing devices for data analysis far exceed the capacity of personal computers. Therefore, providing researchers with a cloud computing platform can create a seamless connection from the scanner to the data inspection and data analysis platform, reduce technical obstacles for neuroimaging researchers, and improve the efficiency of data analysis and the use of computing resources. There are several cloud-based computing platforms available, such as Neuroscience gateway18 and Cbrain19 (see table 1), providing different degrees of flexibility for image analyses. Nevertheless, in terms of ease of use, user familiarity and flexible use of tools, there is still much room for improvement in the computing system for clinical researchers.
To speed up the utilisation of large-scale neuroimaging data, it is necessary to provide a standardised preprocessing pipeline to make the data of multiple research groups comparable and make cross-disease comparison possible. At present, some data-sharing platforms have conducted standardised data mining and analysis attempts. Among them, ENIGMA20 provides ComBat21 scripts to deal with the differences between different sites, and proposes agreements for quality control and analysis of genomics and MRI; for ABIDE dataset,22 preprocessed data using five different image processing pipelines, including CCS (Connectome Computation System),23 C-PAC (Configurable Pipeline for the Analysis of Connectomes),24 DPARSF (Data Processing Assistant for Resting-State fMRI (functional magnetic resonance imaging)),25 CIVET26 and NIAK (Neuroimaging Analysis Kit),27 are shared. In addition, some independent data processing systems, such as volBrain,28 provide automatic brain image processing (skull stripping and brain morphological measures) service and an easy-to-use webpage interface. Furthermore, clinical researchers need a simple and automated multimodal image analysis system to help standardise and simplify neuroimaging preprocessing. To adapt to the cloud storage and management system of neuroimaging data, the pipeline of neuroimaging processing should also be able to be deployed in the cloud and work in connection with the cloud image database. Currently, no system integrates an automated, multi-modal neuroimaging preprocessing and feature extraction pipeline with a cloud database.
In terms of research and clinical transformation of mental disorders, the current neuroimaging research needs to answer questions including the sensitivity and specificity of neuroimaging markers and the dimension of brain abnormalities across mental disorders.29 30 Aggregating multiple types of mental disorders data with similar data quality and similar social and cultural conditions on the same platform is conducive to exploring and testing neuroimaging markers for mental disorders. In addition, based on large-scale and highly homogenous neuroimaging data, artificial intelligence methods will promote the application of neuroimaging technology to the diagnosis and treatment of mental disorders and even the choice of treatment options, thereby bringing technological innovations to the diagnosis and treatment of mental illnesses.
To meet the above challenges, we have developed an integrated and highly automated cloud neuroimaging system, Integrated Neuroimaging Cloud (INCloud). INCloud provides a highly automated cloud solution that connects the acquisition, management, analysis and mining, and clinical applications of neuroimaging data. The aims of INCloud are to (1) enhance the value of neuroimaging information to the scientific research and clinical application of neuropsychiatric diseases; (2) relieve researchers from the complex processes of computational environment deployment, image manipulations and preprocessing; (3) provide efficient facilities for cross-disease and cross-modal analyses and (4) translate research data into resources supporting clinical practice.
Design of INCloud
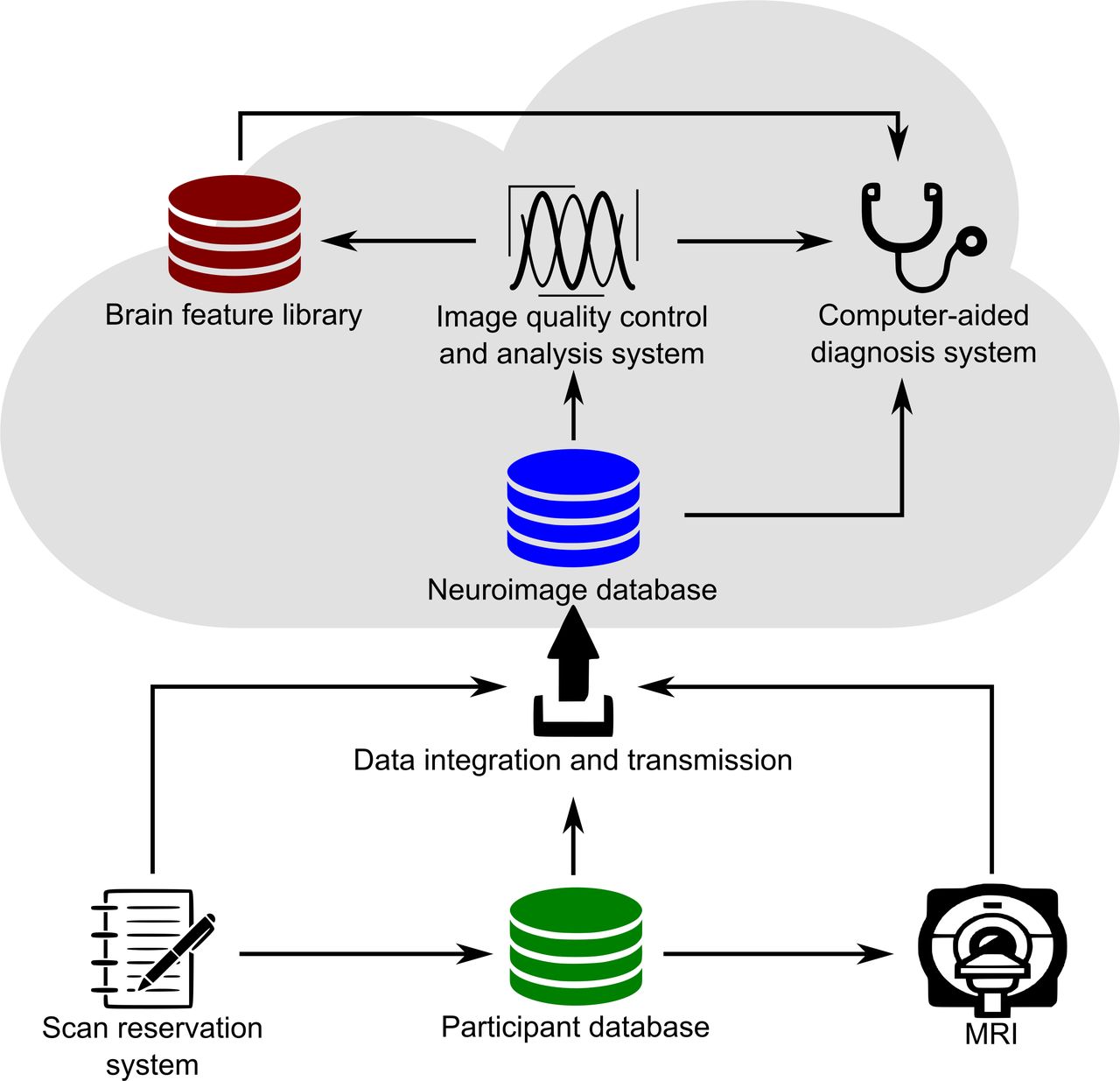
INCloud consists of two main parts, the Neuroimage acquisition system and the Neuroimage computing platform (figure 1). The Neuroimage acquisition system implements functions for scan reservation, basic information acquisition and image data transmission from scanner to cloud. The Neuroimage computing platform serves for data storage/backup, data management, image analyses, brain feature library and clinical services such as computer-aided diagnosis. The arrows in figure 1 indicate the major information flows that connect the functional components.

The overall architecture of INCloud. INCloud, Integrated Neuroimaging Cloud; MRI, magnetic resonance imaging.
Scan reservation system
The neuroimage acquisition system aims to standardise the neuroimage data collection procedures, scan parameters and provides an avenue to connect the images with clinical and historical data. It implements a scan time reservation system that manages the scanners’ operation time slots and user accounts. Meanwhile, the system provides complete sets of commonly used scan sequences and parameter sets for users to choose from and use. Therefore, users can determine the scan sequences and parameters when scheduling a scan. The system encourages users to adopt standardised scanning parameters, so it provides one-key selections of common parameter sets. Users can also customise parameter sets in the system. The scan parameter information selected by the user is passed to the image data transmission system, which will be bound with the image data into the database.
Participant database
The reservation system is connected to the encrypted participant database. The database manages the demographic and major clinical information of the participants, and it can convert the participant’s identity information into an internal unique ID. When users make an appointment for the scanner, they can obtain the internal identifier (ID) of the participants through the participant database. This conversion is essential for securing sensitive information and keeping the data anonymised. The basic information acquisition system can also link previous scans of the same participants and connect to necessary clinical information stored in the hospital information system. After the scan is completed, the participant’s internal ID enters the image data transmission system along with the image data, scan parameter information and so on, to complete the data verification and storage.
Neuroimage database
The neuroimage database is used to manage all neuroimage data. The incoming data are automatically anonymised and backed up. Besides storing the raw image data, the database maintains meta information, such as the internal ID, age, gender, education level and diagnosis categories of the participants, scan date, data owner, sequence name, scan parameters and initial quality assessment. The database also allows data owners to pull their data and authorise other users or user group members to obtain the data.
Image quality control and analysis system
A neuroimage quality control and analysis system is developed to automatically process the multimodal images and extract commonly used brain structural and functional features. This effort helps accelerate the utilisation of neuroimage data and reduce the technical obstacles for clinical researchers to obtain brain measures. The system includes three modules: data conversion, quality control and preprocessing and feature extraction. After converting images from DICOM format to NIFTI format, the quality of the image is evaluated, yielding quality indices such as head motion, signal-to-noise ratio and functional contrast-to-noise ratio. The quality-controlled images are further processed by the preprocessing and feature extraction module. In this module, the neuroimage data of different modalities undergo standardised preprocessing operations, including denoising, spatial transformation, cortical reconstruction of structural images and slice timing correction and registration of functional images. After the image data undergo above standard operations, structural and functional features such as cortical thickness, brain area volume in T1-MPRAGE scans, the amplitude of low-frequency fluctuations, regional homogeneity (ReHo), functional connectivity matrix in BOLD fMRI scans and fractional anisotropy (FA), mean diffusivity (MD) in diffusion tensor imaging (DTI) scans are extracted using a specified parcellation atlas. Both the preprocessed images and the feature tables can be downloaded by authorised users. All the computations are parallelised on a high-performance cluster.
The quality control and image preprocessing system provides a webpage-based user interface for necessary user interactions. After data format conversion, authorised users can manually select which scans enter the automatic processing pipeline. Meanwhile, we provide an interface for users to upload their images to the processing system. After quality control, users and administrators can inspect the quality indices and the images on a webpage to select data for further analyses. When the processing is finished, authorised users can check the quality of the imaging processing, such as the quality of registration, segmentation and parcellation on a webpage. The progress of the processing is also displayed on a webpage with users’ information.
Brain feature library
The brain measures extracted in the analysis system are managed in a neuroimage feature library, combined with demographic and major clinical information. Authorised users can search the library by a variety of conditions regarding the participants and the images. To balance the publicity of information and the protection of users’ private information, we designed the system to display the number of all data items that meet the query conditions, but only list the brain feature data that the current user has sharing permissions for.
Cloud workstation
To provide a flexible, ready-to-use and high-performance platform for customised preprocessing and statistical analyses, we also implement virtual desktops as cloud workstations. Users can access the cloud workstations through Secure Shell (SSH) tunnels or webpages and use them as Linux workstations. The cloud workstations are connected to the neuroimage database, analysis system and feature library, so that users can conduct almost all analyses on the cloud, without the need to download image data to local devices.
Computer-aided diagnosis system
To promote the accumulated data’s value to clinical practice, a computer-aided diagnosis system (CADS) is deployed to learn from the data and provide diagnosis references. The CADS can automatically generate individualised reports for the brain imaging data of specified subjects. The report includes indications of abnormal brain regions and probabilities of diagnostic categories. With the continuous accumulation of image data in INCloud, the internal parameters of CADS are iteratively updated to enhance accuracy.
Functions and advantages
The INCloud provides a full-stack solution for the entire process of large-scale neuroimaging data collection, management, analysis and clinical application. The system has been designed to solve the challenges of the new era of large-scale neuroimaging studies. Figure 2 presents an overview of the INCloud user interface, in which users can launch a variety of functional components.
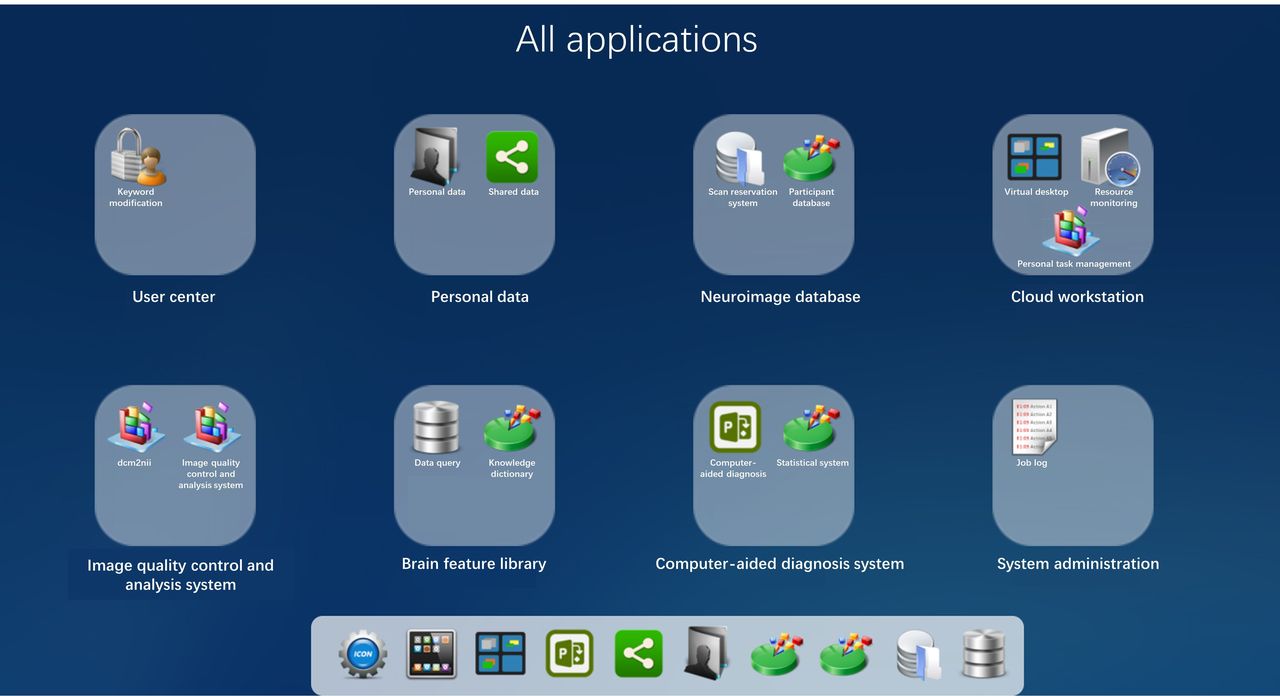
The web interface of the neuroimaging computing platform, showing functional modules available to users.
A unique feature of INCloud is that it integrates the entire process of neuroimaging research, especially neuroimaging research for brain diseases, into a cloud system. There are several advantages of this feature: (1) Throughout the entire process of data acquisition, management and analysis, the image data are all in the INCloud without downloading to the local device, thereby enhancing the data security and operational efficiency. (2) From the starting point, uniform standards, parameters and procedures are applied as much as possible, and consistent processing procedures and computing environments are used during the data analysis. This is conducive to the integration and in-depth utilisation of data. (3) The shared use and dynamic allocation of computing and storage resources help to improve resource utilisation and reduce resource waste caused by repeated construction. (4) Standardised and integrated systems make sure the management of image data does not just stay in the role of ‘network disk’ but refines the managed objects into neuroimaging features. This enables more information contained in neuroimaging to be discovered, used and shared. (5) A complete data collection and analysis chain helps the accumulated neuroimaging data to be conveniently and quickly converted from basic research to clinical services.
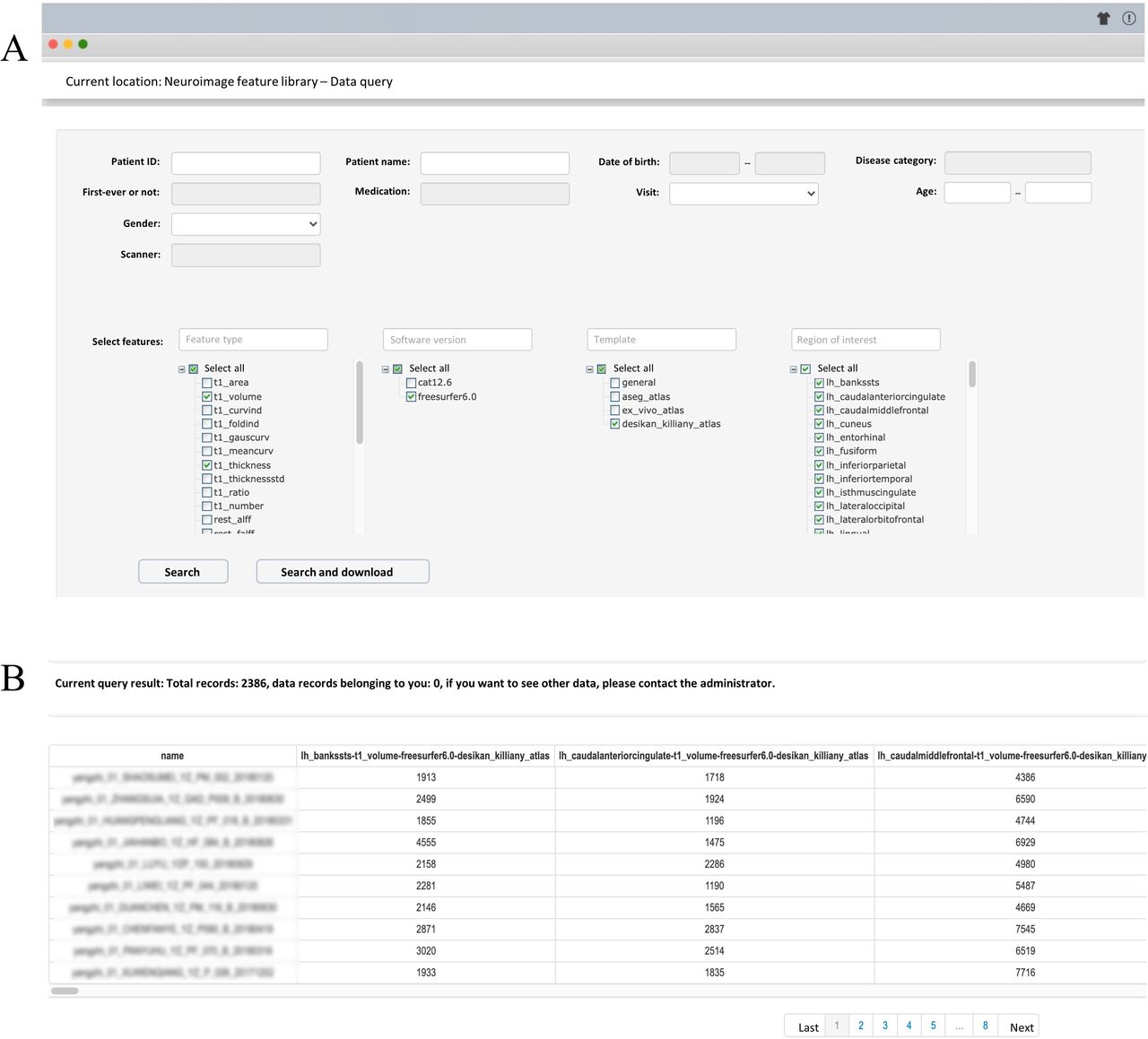
Connecting the image quality control and analysis system to the neuroimage database brings in another novel feature of INCloud, the brain feature library. This database manages image features so that they can be queried, integrated, analysed and shared. Figure 3A shows the query interface of the brain feature library. Users can query brain measures based on the unique ID of a participant, birth date, sex, major diagnostic category, whether it is first-episode, drug medication, with follow-up measures, research project name, age range, scanner, version of the processing pipeline and image quality ratings. Figure 3B presents an example of the query result page. The available features can be viewed on this webpage and downloaded as a table.

The query interface of the brain feature library (A) and the query results (B).
On the one hand, this function helps clinical researchers to obtain image data analysis results in a highly structured form that is ready for statistical analyses, thereby alleviating research difficulties caused by technical reasons, on the other hand, this database can support a new type of brain feature meta-analysis. Researchers can request brain feature data for in-depth analysis for specific scientific questions. This realises the protection of the raw data and also promotes the extensive sharing and mining of brain characteristic information. Different from the existing imaging meta-analyses, the collection and process of the data in the brain feature library have applied consistent standards and procedures, which eliminates many confounding factors and is expected to improve the statistical power of the analysis.
Figure 4 presents a few examples of studies that are conducted using the brain feature library. As an example of a study using real data from INCloud, the researchers first queried and downloaded image feature data across multiple psychiatric disorders through the query interface of the brain feature library. After that, it is possible to conduct a cross-disease investigation on certain brain regions (figure 4A). Both the relationships between brain features in a given population and interpopulational relationships based on multivariate patterns of brain features can be investigated (figure 4B). Furthermore, in the psychiatric research field, there are new research questions towards transdiagnosis. Figure 4C demonstrates transdiagnosis investigations based on multivariate brain features. Meanwhile, the CADS, which is based on the current state-of-the-art artificial intelligence technology and tuned by the large-scale brain feature library, provides clinicians with valuable reference opinions in the diagnosis process, and clinicians can acquire individualised image reports of the patients for references of diagnostic opinions, as shown in figure 4D.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Examples of research that can be carried out based on INCloud. (A) Cross-disease investigation of a certain brain region. (B) Covariation analysis of brain regions across different diseases (a), effect size analysis (b), multivariate pattern analyses (c) and disease similarity analyses (d). (C) Transdiagnostic analysis of dimensions of brain deficits. (D) Development of computer-aided diagnosis system. INCloud,Integrated Neuroimaging Cloud; MR, magnetic resonance.
Summary and outlook
INCloud crystallises the ideas and methods developed in our many years of practice to solve the practical difficulties encountered in large-scale neuroimaging research of brain diseases. At present, INCloud has been deployed and widely used at the Shanghai Mental Health Center and other research and medical institutions. The biggest advantage of this system is that it realises the integrated management and processing of the whole process of neuroimaging research and is optimised for brain disease research, so it is suitable for institutions with brain disease as a major research object. INCloud helps multiple teams work together to collect high-consistency large-scale neuroimaging data and provides high-performance, automated analysis, a data-sharing platform and other functions for such projects. We plan to use cloud servers to make components of INCloud, that is, the image quality control and preprocessing system and cloud workstation available outside the hospital, and we expect this system to make an important contribution to the research of brain diseases. In the future, we will continuously improve INCloud, implementing more choices for the image processing engine, integrating more data-mining algorithms31–35 and further enhancing the accuracy of the CADS.
Data availability statement
Data may be obtained from a third party and are not publicly available.
Ethics statements
Patient consent for publication
Ethics approval
This study does not involve human participants.
Acknowledgments
We acknowledge all members of the Psychiatric Imaging Consortium for sharing data; Shanghai Qianhu Technology Co., Ltd. provided technical assistance for the realisation of INCloud.
References
Qingfeng Li obtained a bachelor's degree and a master's degree of biomedical engineering from Southern Medical University in China in 2017 and 2020, respectively. He is currently an assistant researcher at Laboratory of Psychological Health and Imaging at the Shanghai Mental Health Center, Shanghai Jiao Tong University School of Medicine in Shanghai, China. His main research interests include medical image analysis and development of machine learning-based image processing methods.

Lijuan Jiang obtained a bachelor's degree from Nanchang University School of Medicine in China in 2009 and a master's degree from Fudan University in Shanghai, China in 2012. She is currently an assistant researcher at Laboratory of Psychological Health and Imaging at the Shanghai Mental Health Center, Shanghai Jiao Tong University School of Medicine, Shanghai, China. Her main research interests include early intervention of cognitive aging and neuroimaging of mental disorders.

Footnotes
Twitter @ZhiYang_psy
QL and LJ contributed equally.
Contributors QL and LJ performed the literature search and drafted the manuscript. QL, LJ, KQ, YH, YD, and XZ were involved in building the INCloud. ZY and CL designed the INCloud and edited the manuscript. All authors read and approved the final version of the manuscript. ZY serves as the guarantor who accepts full responsibility for the work and the conduct of the study, had access to the data, and controlled the decision to publish the manuscript.
Funding This work was supported by the National Key R&D Program of China (2018YFC2001605), National Natural Science Foundation of China (81971682, 81571756), Natural Science Foundation of Shanghai (20ZR1472800), Shanghai Municipal Commission of Education (Gaofeng Clinical Medicine-20171929), Shanghai Clinical Research Center for Mental Health (19MC1911100), Shanghai Municipal Health Commission (2019ZB0201, 2018BR17), Shanghai Science and Technology Commission (18JC1420305), Shanghai Mental Health Center Clinical Research Center (CRC2018DSJ01-5, CRC2019ZD04), and Research Funds from Shanghai Mental Health Center (13dz2260500, 2018-YJ-02).
Competing interests None declared.
Provenance and peer review Commissioned; externally peer reviewed.